【Python】自学整理
本文最后更新于:2023年2月20日 凌晨
你可以将余生都用来学习Python和编程的纷繁难懂之处,但这样你什么项目都完不成。不要企图编写完美无缺的代码;先编写行之有效的代码,再决定是对其做进一步改进,还是转而去编写新代码。
————Eric Matthes
Python之禅
1 | |
Let’s start with————print("Hello,world!")
第一部分 基础知识
第一章 起步
安装及配置环境_略
vscode is good
访问浏览Python.org ,以浏览天书
https://docs.python.org/zh-cn/3/
第二章 变量和简单数据类型
变量的命名与使用
变量在程序中可以随时修改其值,而Python将始终记录变量的最新值。
有关变量的规则:
- 变量名只能包含字母、数字和下划线。变量名可以字母或下划线打头,但不能以数字打头,例如,可将变量命名为
message_1,但不能将其命名为1_message。 - 变量名不能包含空格,但可使用下划线来分隔其中的单词。例如,变量名
greeting_message可行,但变量名greeting message会引发错误。 - 不要将Python关键字和函数名用作变量名,即不要使用Python保留用于特殊用途的单词如print (请参见附录A.4)。
- 变量名应既简短又具有描述性。例如,
name比n好,student_name比s_n好,name_length比length_of_persons_name好。 - 慎用小写字母1和大写字母O,因为它们可能被人错看成数字1和0。
使用变量时避免命名错误
字符串
在Python中,用引号括起的都是字符串,其中的引号可以是单引号,也可以是双引号,如下所示:
1 | |
这种灵活性能让你能够在字符串中包含 " "和 ' ':
1 | |
使用方法修改字符串大小写
1 | |
输出依次为:
1 | |
在print()语句中,方法 title()出现在这个变量的后面。 方法Method是Python可对数据执行的操作。在name.title()中, name后面的句点 .让Python对变量name执行方法 title()指定的操作。每个方法后面都跟着一对括号,这是因为方法通常需要额外的信息来完成其工作。这种信息是在括号内提供的。函数 title()不需要额外的信息,因此它后面的括号是空的。
存储数据时,方法lower()很有用。很多时候,你无法依靠用户来提供正确的大小写,因此需要将字符串先转换为小写,再存储它们。以后需要显示这些信息时,再将其转换为最合适的大小写方式。
合并、拼接字符串
Python使用加号 +来合并字符串,这种合并字符串的方法称为拼接。通过拼接,可使用存储在变量中的信息来创建完整的消息,例如:
1 | |
使用制表符或换行符来添加空白
空白泛指任何非打印字符,如空格、制表符 \t和换行符 \n。
反斜杠 \用于转义。
1 | |
如果不希望前置 \的字符转义成特殊字符,可以使用 原始字符串,在引号前添加 r 即可:
删除空白
对变量调用方法 rstrip()后,多余的空格将被删除。然而,这种删除只是暂时的,接下来再次访问变量值时仍然有空格,要永久删除这个字符串中的空白,必须将删除操作的结果存回到变量中。分别使用方法 lstrip()和 strip()可以删除变量左端(开头)和右端(末尾)的空格,例:
1 | |
避免语法错误
语法错误(SyntaxError: invalid syntax)是一种时不时会遇到的错误。程序中包含非法的Python代码时,就会导致语法错误。
例如,在用单引号括起的字符串中,如果包含撇号,就将导致错误。这是因为这会导致Python将第一个单引号和撇号之间的内容视为一个字符串,进而将余下的文本视为Python代码,从而引发错误。
数字
整数(int)
运算符 +、-、*、/ 的用法和其他大部分语言一样;括号 ( ) 用来分组;用 **运算符计算乘方;等号 =用于给变量赋值,赋值后,下一个交互提示符的位置不显示任何结果。
注:** 比 - 的优先级更高, 所以 -3**2 会被解释成 -(3**2) ,因此,结果是 -9。要避免这个问题,并且得到 9, 可以用 (-3)**2。
浮点数(float)
Python 全面支持浮点数;混合类型运算数的运算会把整数转换为浮点数;交互模式下,上次输出的表达式会赋给变量 _。把 Python 当作计算器时,用该变量实现下一步计算更简单,例如:
如果变量未定义(即,未赋值),使用该变量会提示错误:NameError: name 'n' is not defined。
交互模式下,上次输出的表达式会赋给变量 _。把 Python 当作计算器时,用该变量实现下一步计算更简单,例如:
但需要注意的是,结果包含的小数位数可能是不确定的:
1 | |
所有语言都存在这种问题,没有什么可担心的。 Python会尽力找到一种方式,以尽可能精确地表示结果,但鉴于计算机内部表示数字的方式,这在有些情况下很难。就现在而言,暂时忽略多余的小数位数即可;在第二部分的项目中,你将学习在需要时处理多余小数位的方式。
函数str()的使用
函数str()让Python将非字符串值表示为字符串。
注释
在Python中,注释用井号 #标识,井号后面的内容都会被Python解释器忽略。
编写注释的主要目的是阐述代码要做什么,以及是如何做的。在开发项目期间,你对各个部分如何协同工作了如指掌,但过段时间后,有些细节你可能不记得了。当然,你总是可以通过研究代码来确定各个部分的工作原理,但通过编写注释,以清晰的自然语言对解决方案进行概述,可节省很多时间。要成为专业程序员或与其他程序员合作,就必须编写有意义的注释。当前,大多数软件都是合作编写的,编写者可能是同一家公司的多名员工,也可能是众多致力于同一个开源项目的人员。
训练有素的程序员都希望代码中包含注释,因此你最好从现在开始就在程序中添加描述性注释。作为新手,最值得养成的习惯之一是,在代码中编写清晰、简洁的注释。如果不确定是否要编写注释,就问问自己,找到合理的解决方案前,是否考虑了多个解决方案。如果答案是肯定的,就编写注释对你的解决方案进行说明吧。相比回过头去再添加注释,删除多余的注释要容易得多。
最喜欢的事情:别人写注释
最讨厌的事情:自己写注释
第三章 列表
列表是什么
在Python中,用方括号( [])来表示列表,并用逗号来分隔其中的元素。下面是一个简单的列表示例:
1 | |
访问列表元素
列表是有序集合,因此要访问列表的任何元素,只需将该元素的位置或索引告诉Python即可。要访问列表元素,可指出列表的名称,再指出元素的索引,并将其放在方括号内。当你请求获取列表元素时,Python只返回该元素,而不包括方括号和引号。
1 | |
索引从0开始
在Python中,第一个列表元素的索引为0,而不是1。在大多数编程语言中都是如此,这与列表操作的底层实现相关。
Python为访问最后一个列表元素提供了一种特殊语法。通过将索引指定为-1,可让Python返回最后一个列表元素这种语法很有用,因为你经常需要在不知道列表长度的情况下访问最后的元素。这种约定也适用于其他负数索引,例如,索引-2返回倒数第二个列表元素,索引-3返回倒数第三个列表元素,以此类推。
修改、添加和删除元素
你创建的大多数列表都将是动态的,这意味着列表创建后,将随着程序的运行增删元素。
修改列表元素
修改列表元素的语法与访问列表元素的语法类似。要修改列表元素,可指定列表名和要修改
的元素的索引,再指定该元素的新值。
例如,依旧是上述列表 bicycles = ['trek', 'cannondale', 'redline', 'specialized'],修改第一个元素的值的操作如下:
1 | |
你可以修改任何列表元素的值,而不仅仅是第一个元素的值。
在列表中添加元素
在列表末尾添加元素
在列表中添加新元素时,最简单的方式是将元素附加到列表末尾。使用方法 append()给列表附加元素时,它将添加到列表末尾。例:
1 | |
输出结果为:
1 | |
方法 append()让动态地创建列表易如反掌,例如,你可以先创建一个空列表,再使用一系列的 append()语句添加元素。这种创建列表的方式极其常见,因为经常要等程序运行后,你才知道用户要在程序中存储哪些数据。为控制用户,可首先创建一个空列表,用于存储用户将要输入的值,然后将用户提供的每个新值附加到列表中。
在列表中插入元素
使用方法 insert()可在列表的任何位置添加新元素。为此,你需要指定新元素的索引和值。
1 | |
插入到该位置后,该位置及其之后的所有元素往后移一位。
从列表中删除元素
使用del语句删除元素
使用del可删除任何位置处的列表元素,条件是知道其索引。
1 | |
使用方法pop()删除元素
方法 pop()可删除列表末尾的元素,并让你能够接着使用它。术语弹出(pop)源自这样的类比:列表就像一个栈,而删除列表末尾的元素相当于弹出栈顶元素。
下面从列表motorcycles中弹出一款摩托车:
1 | |
输出结果:
1 | |
弹出列表中任何位置处的元素
实际上,你可以使用pop()来删除列表中任何位置的元素,只需在括号中指定要删除的元素的索引即可。
p.s:如果你不确定该使用del语句还是pop()方法,下面是一个简单的判断标准:如果你要从列表中删除一个元素,且不再以任何方式使用它,就使用del语句;如果你要在删除元素后还能继续使用它,就使用方法pop()。
根据值删除元素
如果你只知道要删除的元素的值,可使用方法 remove()。
1 | |
注意:方法remove()只删除第一个指定的值。如果要删除的值可能在列表中出现多次,就需要使用循环来判断是否删除了所有这样的值。
组织列表
使用方法sort()对列表进行永久性排序
Python方法 sort()让你能够较为轻松地对列表进行排序。
例:
1 | |
输出结果:
1 | |
sort(*, key=None, reverse=False)此方法会对列表进行原地排序,只使用 < 来进行各项间比较。异常不会被屏蔽————如果有任何比较操作失败,整个排序操作将失败(而列表可能会处于被部分修改的状态)。reverse为一个布尔值。如果设为 True,则每个列表元素将按反向顺序比较进行排序,例:
1 | |
输出结果:
1 | |
使用函数 sorted()对列表进行临时排序
要保留列表元素原来的排列顺序,同时以特定的顺序呈现它们,可使用函数 sorted()。函数 sorted()让你能够按特定顺序显示列表元素,同时不影响它们在列表中的原始排列顺序。
1 | |
p.s:在并非所有的值都是小写时,按字母顺序排列列表要复杂些。决定排列顺序时,有多种解读大写字母的方式,要指定准确的排列顺序,可能比我们这里所做的要复杂。然而,大多数排序方式都基于本节介绍的知识。
倒着打印列表
要反转列表元素的排列顺序,可使用方法reverse()。注意, reverse()不是指按与字母顺序相反的顺序排列列表元素,而只是反转列表元素的排列顺序。方法reverse()永久性地修改列表元素的排列顺序,但可随时恢复到原来的排列顺序,为此只需对列表再次调用reverse()即可。
1 | |
确定列表长度
使用函数len()可快速获悉列表的长度。
1 | |
Python计算列表元素数时从1开始,因此确定列表长度时,应该不会遇到差一错误。
使用列表时避免索引错误
索引错误 IndexError: list index out of range。索引错误意味着Python无法理解你指定的索引。每当需要访问最后一个列表元素时,都可使用索引-1。这在绝大多数情况下都行之有效,仅当列表为空时,这种访问最后一个元素的方式才会导致错误。
发生索引错误却找不到解决办法时,请尝试将列表或其长度打印出来。列表可能与你以为的截然不同,在程序对其进行了动态处理时尤其如此。通过查看列表或其包含的元素数,可帮助你找出这种逻辑错误。
第四章 操作列表
遍历列表
1 | |
刚开始使用循环时请牢记,对列表中的每个元素,都将执行循环指定的步骤,而不管列表包含多少个元素。在for循环后面,没有缩进的代码都只执行一次,而不会重复执行。
使用列表时常出现的错误
Python根据缩进来判断代码行与前一个代码行的关系。Python通过使用缩进让代码更易读;简单地说,它要求你使用缩进让代码整洁而结构清晰。在较长的Python程序中,你将看到缩进程度各不相同的代码块,这让你对程序的组织结构有大致的认识。
忘记缩进
IndentationError: expected an indented block通常,将紧跟在for语句后面的代码行缩进,可消除这种缩进错误。
忘记缩进额外的代码行
这是一个逻辑错误。从语法上看,这些Python代码是合法的,但由于存在逻辑错误,结果并不符合预期。
不必要的缩进
IndentationError: unexpected indent为避免意外缩进错误,请只缩进需要缩进的代码。
遗漏了冒号
创建数值列表
使用函数range()创建数字列表
Python函数 range()让你能够轻松地生成一系列的数字。
要打印数字1~5,需要使用range(1,6):
1 | |
这样,输出将从1开始,到5结束:
1 | |
数range()让Python从你指定的第一个值开始数,并在到达你指定的第二个值后停止。
要创建数字列表,可使用函数list()将range()的结果直接转换为列表。
使用函数range()时,还可指定步长。例如,下面的代码打印1~10内的偶数:
1 | |
在这个示例中,函数range()从2开始数,然后不断地加2,直到达到或超过终值(11),因此输出如下:
1 | |
对数字列表执行简单的统计计算
有几个专门用于处理数字列表的Python函数。例如,你可以轻松地找出数字列表的最大值、最小值和总和:
1 | |
列表解析
列表解析将for循环和创建新元素的代码合并成一行,并自动附加新元素。
例:
1 | |
要使用这种语法,首先指定一个描述性的列表名,如squares;然后,指定一个左方括号,并定义一个表达式,用于生成你要存储到列表中的值。在这个示例中,表达式为 value**2,它计算平方值。接下来,编写一个for循环,用于给表达式提供值,再加上右方括号。在这个示例中,for循环为 for value in range(1,11),它将值1~10提供给表达式 value**2。请注意,这里的for
语句末尾没有冒号。
1 | |
使用列表的一部分
你可以处理列表的部分元素——Python称之为切片。
切片
要创建切片,可指定要使用的第一个元素和最后一个元素的索引。与
1 | |
你可以生成列表的任何子集,需要注意的是,函数range()一样, Python在到达你指定的第二个索引前面的元素后停止。
如果你没有指定第一个索引, Python将自动从列表开头开始 列表名[;索引];要让切片终止于列表末尾,也可使用类似的语法 列表名[索引;],无论列表多长,这种语法都能够让你输出从特定位置到列表末尾的所有元素。
负数索引返回离列表末尾相应距离的元素,因此你可以输出列表末尾的任何切片。例如,如果你要输出列表最后三个元素,可使用切片 列表名[-3:]。
遍历切片
如果要遍历列表的部分元素,可在for循环中使用切片,例如:
1 | |
复制列表
要复制列表,可创建一个包含整个列表的切片,方法是同时省略起始索引和终止索引 [:]。这让Python创建一个始于第一个元素,终止于最后一个元素的切片,即复制整个列表。
元组
Python将不能修改的值称为不可变的,而不可变的列表被称为元组。
定义元组
元组看起来犹如列表,但使用圆括号而不是方括号来标识。定义元组后,就可以使用索引来访问其元素,就像访问列表元素一样。
例如,如果有一个大小不应改变的矩形,可将其长度和宽度存储在一个元组中,从而确保它们是不能修改的:
1 | |
我们首先定义了元组dimensions,为此我们使用了圆括号而不是方括号。接下来,我
们分别打印该元组的各个元素:
1 | |
下面来尝试修改元组dimensions中的一个元素:
1 | |
代码试图修改第一个元素的值,导致Python返回类型错误消息。由于试图修改元组的
操作是被禁止的,因此Python指出不能给元组的元素赋值:
1 | |
代码试图修改矩形的尺寸时, Python报告错误。
遍历元组中的所有值
1 | |
修改元组变量
虽然不能修改元组的元素,但可以给存储元组的变量赋值。因此,如果要修改前述矩形的尺寸,可重新定义整个元组。这次, Python不会报告任何错误,因为给元组变量赋值是合法的:
1 | |
输出结果:
1 | |
相比于列表,元组是更简单的数据结构。如果需要存储的一组值在程序的整个生命周期内都不变,可使用元组。
设置代码格式
随着你编写的程序越来越长,有必要了解一些代码格式设置约定。请花时间让你的代码尽可能易于阅读;让代码易于阅读有助于你掌握程序是做什么的,也可以帮助他人理解你编写的代码。为确保所有人编写的代码的结构都大致一致, Python程序员都遵循一些格式设置约定。学会编写整洁的Python后,就能明白他人编写的Python代码的整体结构——只要他们和你遵循相同的指南。要成为专业程序员,应从现在开始就遵循这些指南,以养成良好的习惯。
格式设置指南
若要提出Python语言修改建议,需要编写Python改进提案( Python Enhancement Proposal,PEP)。 PEP 8是最古老的PEP之一,它向Python程序员提供了代码格式设置指南。 PEP 8的篇幅很
长,但大都与复杂的编码结构相关。Python格式设置指南的编写者深知,代码被阅读的次数比编写的次数多。代码编写出来后,调试时你需要阅读它;给程序添加新功能时,需要花很长的时间阅读代码;与其他程序员分享代码时,这些程序员也将阅读它们。如果一定要在让代码易于编写和易于阅读之间做出选择, Python程序员几乎总是会选择后者。下面的指南可帮助你从一开始就编写出清晰的代码。
缩进
PEP 8建议每级缩进都使用四个空格,这既可提高可读性,又留下了足够的多级缩进空间。在字处理文档中,大家常常使用制表符而不是空格来缩进。对于字处理文档来说,这样做的效果很好,但混合使用制表符和空格会让Python解释器感到迷惑。每款文本编辑器都提供了一种设置,可将输入的制表符转换为指定数量的空格。你在编写代码时应该使用制表符键,但一定要对编辑器进行设置,使其在文档中插入空格而不是制表符。在程序中混合使用制表符和空格可能导致极难解决的问题。如果你混合使用了制表符和空格,可将文件中所有的制表符转换为空格,大多数编辑器都提供了这样的功能。
行长
很多Python程序员都建议每行不超过80字符。最初制定这样的指南时,在大多数计算机中,终端窗口每行只能容纳79字符;当前,计算机屏幕每行可容纳的字符数多得多,为何还要使用79字符的标准行长呢?这里有别的原因。专业程序员通常会在同一个屏幕上打开多个文件,使用标准行长可以让他们在屏幕上并排打开两三个文件时能同时看到各个文件的完整行。 PEP 8还建议注释的行长都不超过72字符,因为有些工具为大型项目自动生成文档时,会在每行注释开头添加格式化字符。PEP 8中有关行长的指南并非不可逾越的红线,有些小组将最大行长设置为99字符。在学习期间,你不用过多地考虑代码的行长,但别忘了,协作编写程序时,大家几乎都遵守PEP 8指南。在大多数编辑器中,都可设置一个视觉标志——通常是一条竖线,让你知道不能越过的界线在什么地方。
空行
要将程序的不同部分分开,可使用空行。你应该使用空行来组织程序文件,但也不能滥用;只要按本书的示例展示的那样做,就能掌握其中的平衡。例如,如果你有5行创建列表的代码,还有3行处理该列表的代码,那么用一个空行将这两部分隔开是合适的。然而,你不应使用三四个空行将它们隔开。空行不会影响代码的运行,但会影响代码的可读性。 Python解释器根据水平缩进情况来解读代码,但不关心垂直间距。
其他格式设置指南
PEP 8还有很多其他的格式设置建议,但这些指南针对的程序大都比目前为止本书提到的程序复杂。等介绍更复杂的Python结构时,我们再来分享相关的PEP 8指南。请访问 https://python.org/dev/peps/pep-0008/,阅读 PEP 8 格式设置指南。当前,这些指南适用的不多,但可以大致浏览一下.
第五章 if语句
条件测试
每条if语句的核心都是一个值为True或False的表达式,这种表达式被称为条件测试。 Python根据条件测试的值为True还是False来决定是否执行if语句中的代码。如果条件测试的值为 True,Python就执行紧跟在if语句后面的代码;如果为 False, Python就忽略这些代码。
检查是否相等
大多数条件测试都将一个变量的当前值同特定值进行比较。最简单的条件测试检查变量的值是否与特定值相等: 变量A == 变量B
在Python中检查是否相等时区分大小写,例如,两个大小写不同的值会被视为不相等。
检查是否不相等
要判断两个值是否不等,可结合使用惊叹号和等号 !=,其中的惊叹号表示不,在很多编程语言中都如此。
比较数字
条件语句中可包含各种数学比较,如等于 ==、不等于 !=、小于 <、小于等于 <=、大于 >、大于等于 >=。
检查多个条件
使用and检查多个条件
要检查是否两个条件都为True,可使用关键字and将两个条件测试合而为一;如果每个测试都通过了,整个表达式就为True;如果至少有一个测试没有通过,整个表达式就为False。
使用or检查多个条件
关键字or也能够让你检查多个条件,但只要至少有一个条件满足,就能通过整个测试。仅当两个测试都没有通过时,使用or的表达式才为False。
检查特定值是否包含在列表中
要判断特定的值是否已包含在列表中,可使用关键字 in。条件表达式为 元素 in 列表。
关键字 in让Python检查列表中是否包含特定元素。这让你能够在创建一个列表后,轻松地检查其中是否包含特定的值。
有些时候,确定特定的值未包含在列表中很重要;在这种情况下,可使用关键字 not in,条件表达式与in类似。
布尔表达式
随着对编程的了解越来越深入,将遇到术语布尔表达式,它不过是条件测试的别名。与条件表达式一样,布尔表达式的结果要么为True,要么为False。布尔值通常用于记录条件,如游戏是否正在运行,或用户是否可以编辑网站的特定内容:
1 | |
在跟踪程序状态或程序中重要的条件方面,布尔值提供了一种高效的方式。
if语句
理解条件测试后,就可以开始编写if语句了。
最简单的if语句只有一个测试和一个操作:
1 | |
在第1行中,可包含任何条件测试,而在紧跟在测试后面的缩进代码块中,可执行任何操作。如果条件测试的结果为True, Python就会执行紧跟在if语句后面的代码;否则Python将忽略这些代码。在紧跟在if语句后面的代码块中,可根据需要包含任意数量的代码行。
if-else语句
经常需要在条件测试通过了时执行一个操作,并在没有通过时执行另一个操作;在这种情况下,可使用Python提供的if-else语句。 if-else语句块类似于简单的if语句,但其中的else语句让你能够指定条件测试未通过时要执行的操作。
1 | |
if-elif-else结构
经常需要检查超过两个的情形,为此可使用Python提供的if-elif-else结构。 Python只执行if-elif-else结构中的一个代码块,它依次检查每个条件测试,直到遇到通过了的条件测试。测试通过后, Python将执行紧跟在它后面的代码,并跳过余下的测试。
在现实世界中,很多情况下需要考虑的情形都超过两个。例如,来看一个根据年龄段收费的游乐场:
- 4岁以下免费;
- 4~18岁收费5美元;
- 18岁(含)以上收费10美元。
如果只使用一条if语句,如何确定门票价格呢?下面的代码确定一个人所属的年龄段,并打印一条包含门票价格的消息:
1 | |
可根据需要使用任意数量的elif代码块。
Python并不要求if-elif结构后面必须有else代码块。在有些情况下, else代码块很有用;而在其他一些情况下,使用一条elif语句来处理特定的情形更清晰。
else是一条包罗万象的语句,只要不满足任何if或elif中的条件测试,其中的代码就会执行,这可能会引入无效甚至恶意的数据。如果知道最终要测试的条件,应考虑使用一个elif代码块来代替else代码块。这样,你就可以肯定,仅当满足相应的条件时,你的代码才会执行。
注意
if-elif-else结构功能强大,但仅适合用于只有一个条件满足的情况:遇到通过了的测试后,Python就跳过余下的测试。这种行为很好,效率很高,让你能够测试一个特定的条件。
总之,如果你只想执行一个代码块,就使用if-elif-else结构;如果要运行多个代码块,就使用一系列独立的if语句。
使用if语句处理列表
通过结合使用if语句和列表,可完成一些有趣的任务:对列表中特定的值做特殊处理;高效地管理不断变化的情形。
检查特殊元素
1 | |
确定列表不是空的
到目前为止,对于处理的每个列表都做了一个简单的假设,即假设它们都至少包含一个元素。我们马上就要让用户来提供存储在列表中的信息,因此不能再假设循环运行时列表不是空的。有鉴于此,在运行for循环前确定列表是否为空很重要。
在if语句中将列表名用在条件表达式中时, Python将在列表至少包含一个元素时返回True,并在列表为空时返回False。
1 | |
第六章 字典
字典
在Python中, 字典是一系列键—值对(key-value)。每个键都与一个值相关联,你可以使用键来访问与之相关联的值。与键相关联的值可以是数字、字符串、列表乃至字典。事实上,可将任何Python对象用作字典中的值。
定义字典
在Python中,字典用放在花括号{}中的一系列键—值对表示,如示例所示:
1 | |
键—值对是两个相关联的值。指定键时, Python将返回与之相关联的值。键和值之间用冒号分隔,而键—值对之间用逗号分隔。在字典中,你想存储多少个键—值对都可以。
访问字典中的值
要获取与键相关联的值,可依次指定字典名和放在方括号内的键 字典名[键名],如示例所示:
1 | |
这将返回字典alien_0中与键’color’相关联的值。
添加key-value对
字典是一种动态结构,可随时在其中添加键—值对。要添加键—值对,可依次指定字典名、用方括号括起的键和相关联的值,格式为 字典名[新的键] = 值。
注意,键—值对的排列顺序与添加顺序不同。 Python不关心键—值对的添加顺序,而只关心键和值之间的关联关系。
先创建一个空字典
有时候,在空字典中添加键—值对是为了方便,而有时候必须这样做。为此,可先使用一对空的花括号定义一个字典,再分行添加各个键—值对。
例如,下例演示了如何以这种方式创建字典 alien_0:
1 | |
输出结果为:
1 | |
使用字典来存储用户提供的数据或在编写能自动生成大量键—值对的代码时,通常都需要先定义一个空字典。
修改字典中的值
要修改字典中的值,可依次指定字典名、用方括号括起的键以及与该键相关联的新值,类似于创建新的键-值对。
删除key-value对
对于字典中不再需要的信息,可使用del语句将相应的键—值对彻底删除。使用 del语句时,必须指定字典名和要删除的键。
1 | |
删除的键—值对永远消失了。
确定需要使用多行来定义字典时,在输入左花括号后按回车键,再在下一行缩进四个空格,指定第一个键—值对,并在它后面加上一个逗号。此后你再次按回车键时,文本编辑器将自动缩进后续键—值对,且缩进量与第一个键—值对相同。
1 | |
定义好字典后,在最后一个键—值对的下一行添加一个右花括号,并缩进四个空格,使其与字典中的键对齐。另外一种不错的做法是在最后一个键—值对后面也加上逗号,为以后在下一行添加键—值对做好准备。
对于较长的列表和字典,大多数编辑器都有以类似方式设置其格式的功能。对于较长的字典,还有其他一些可行的格式设置方式,因此在你的编辑器或其他源代码中,你可能会看到稍微不同的格式设置方式。
遍历字典
一个Python字典可能只包含几个键—值对,也可能包含数百万个键—值对。鉴于字典可能包含大量的数据, Python支持对字典遍历。字典可用于以各种方式存储信息,因此有多种遍历字典的方式:可遍历字典的所有键—值对、键或值。
遍历所有key-value对
要编写用于遍历字典的for循环,可声明两个变量,用于存储键—值对中的键和值。对于这两个变量,可使用任何名称,一般来说,会使用与字典储存元素相关的描述性名称作为变量名,给阅读代码带来便利。
可以使用方法 items(),它返回一个键—值对列表。接下来,for循环依次将每个键—值对存储到指定的两个变量中。
1 | |
注意,即便遍历字典时,键—值对的返回顺序也与存储顺序不同。 Python不关心键—值对的存储顺序,而只跟踪键和值之间的关联关系。
遍历字典中的所有键
在不需要使用字典中的值时,方法 keys()很有用。
1 | |
遍历字典时,会默认遍历所有的键,因此,如果将上述代码中的 for name in favorite_languages.keys():替换为 for name in favorite_languages:,输出将不变。
如果显式地使用方法 keys()可让代码更容易理解,你可以选择这样做,但如果你愿意,也可省略它。在这种循环中,可使用当前键来访问与之相关联的值。
我们像前面一样遍历字典中的名字,但在名字为指定朋友的名字时,打印一条消息,指出其喜欢的语言:
1 | |
我们创建了一个列表,其中包含我们要通过打印消息,指出其喜欢的语言的朋友。在循环中,我们打印每个人的名字,并检查当前的名字是否在列表friends中。如果在列
表中,就打印一句特殊的问候语,其中包含这位朋友喜欢的语言。为访问喜欢的语言,我们使用了字典名,并将变量name的当前值作为键。每个人的名字都会被打印,但只对朋友打印特殊消息:
1 | |
方法 keys()并非只能用于遍历;实际上,它返回一个列表,其中包含字典中的所有键。
按顺序遍历字典中的所有键
字典总是明确地记录键和值之间的关联关系,但获取字典的元素时,获取顺序是不可预测的。这不是问题,因为通常你想要的只是获取与键相关联的正确的值。
要以特定的顺序返回元素,一种办法是在for循环中对返回的键进行排序。为此,可使用函数 sorted()来获得按特定顺序排列的键列表的副本:
1 | |
这条for语句类似于其他for语句,但对方法 dictionary.keys()的结果调用了函数sorted()。这让Python列出字典中的所有键,并在遍历前对这个列表进行排序。
遍历字典中的所有值
如果你感兴趣的主要是字典包含的值,可使用方法 values(),它返回一个值列表,而不包含任何键。
1 | |
这条for语句提取字典中的每个值,并将它们依次存储到变量中。
这种做法提取字典中所有的值,而没有考虑是否重复。涉及的值很少时,这也许不是问题,但如果被调查者很多,最终的列表可能包含大量的重复项。为剔除重复项,可使用集合 set。集合类似于列表,但每个元素都必须是独一无二的
1 | |
通过对包含重复元素的列表调用 set(),可让Python找出列表中独一无二的元素,并使用这些元素来创建一个集合。
嵌套
有时候,需要将一系列字典存储在列表中,或将列表作为值存储在字典中,这称为嵌套。你可以在列表中嵌套字典、在字典中嵌套列表甚至在字典中嵌套字典。
字典列表
在下面的示例中,我们使用range()生成了30个外星人:
1 | |
在这个示例中,首先创建了一个空列表,用于存储接下来将创建的所有外星人。range()返回一系列数字,其唯一的用途是告诉Python我们要重复这个循环多少次。每次执行这个循环时,都创建一个外星人,并将其附加到列表aliens末尾。
经常需要在列表中包含大量的字典,而其中每个字典都包含特定对象的众多信息。在这个列表中,所有字典的结构都相同,因此你可以遍历这个列表,并以相同的方式处理其中的每个字典。
在字典中储存列表
有时候,需要将列表存储在字典中,而不是将字典存储在列表中。
每当需要在字典中将一个键关联到多个值时,都可以在字典中嵌套一个列表,例:
1 | |
列表和字典的嵌套层级不应太多。
在字典中存储字典
可在字典中嵌套字典,但这样做时,代码可能很快复杂起来。例如,如果有多个网站用户,每个都有独特的用户名,可在字典中将用户名作为键,然后将每位用户的信息存储在一个字典中,并将该字典作为与用户名相关联的值。
1 | |
我们首先定义了一个名为users的字典,其中包含两个键:用户名’aeinstein’和’mcurie’;与每个键相关联的值都是一个字典,其中包含用户的名、姓和居住地。在处,我们遍历字典users,让Python依次将每个键存储在变量username中,并依次将与当前键相关联的字典存储在变量user_info中。在主循环内部,我们将用户名打印出来。
接下来开始访问内部的字典。变量user_info包含用户信息字典,而该字典包含三个键’first’、 ‘last’和’location’;对于每位用户,我们都使用这些键来生成整洁的姓名和居住地,然后打印有关用户的简要信息:
1 | |
请注意,表示每位用户的字典的结构都相同,虽然Python并没有这样的要求,但这使得嵌套的字典处理起来更容易。倘若表示每位用户的字典都包含不同的键, for循环内部的代码将更复杂。
第七章 用户输入和while循环
大多数程序都旨在解决最终用户的问题,为此通常需要从用户那里获取一些信息。
函数input()的工作原理
函数 input()让程序暂停运行,等待用户输入一些文本。获取用户输入后, Python将其存储在一个变量中,以方便你使用。函数 input()接受一个参数:即要向用户显示的提示或说明,让用户知道该如何做。程序等待用户输入,并在用户按回车键后继续运行。
1 | |
编写清晰的程序
每当你使用函数input()时,都应指定清晰而易于明白的提示,准确地指出你希望用户提供什么样的信息——指出用户该输入任何信息的提示都行。通过在提示末尾包含一个空格,可将提示与用户输入分开,让用户清楚地知道其输入始于何处。
有时候,提示可能超过一行,例如,你可能需要指出获取特定输入的原因。在这种情况下,可将提示存储在一个变量中,再将该变量传递给函数input()。这样,即便提示超过一行, input()语句也非常清晰。
1 | |
使用int()来获取数值输入
使用函数input()时, Python将用户输入解读为字符串。请看下面让用户输入其年龄的解释器会话:
1 | |
用户输入的数值被以字符串表示。离谱想让Python将输入视为数值,可使用函数int(),函数int()将数字的字符串表示转换为数值表示。
求模运算符%
处理数值信息时, 求模运算符( %)是一个很有用的工具,它将两个数相除并返回余数。求模运算符不会指出一个数是另一个数的多少倍,而只指出余数是多少。如果一个数可被另一个数整除,余数就为0,因此求模运算符将返回0。你可利用这一点来判断一个数是奇数还是偶数:
1 | |
while循环
while 语句用于在表达式保持为真的情况下重复地执行:
1 | |
这将重复地检验表达式,并且如果其值为真就执行第一个子句体;如果表达式值为假(这可能在第一次检验时就发生)则如果 else 子句体存在就会被执行并终止循环。
让用户选择何时退出
例:
1 | |
等到用户终于输入’quit’后, Python停止执行while循环,而整个程序也到此结束。
使用标志
在前一个示例中,我们让程序在满足指定条件时就执行特定的任务。但在更复杂的程序中,很多不同的事件都会导致程序停止运行;在这种情况下,该怎么办呢?例如,在游戏中,多种事件都可能导致游戏结束,如玩家一艘飞船都没有了或要保护的城市都被摧毁了。导致程序结束的事件有很多时,如果在一条while语句中检查所有这些条件,将既复杂又困难。
在要求很多条件都满足才继续运行的程序中,可定义一个变量,用于判断整个程序是否处于活动状态。这个变量被称为标志,充当了程序的交通信号灯。你可让程序在标志为True时继续运行,并在任何事件导致标志的值为False时让程序停止运行。这样,在while语句中就只需检查一个条件——标志的当前值是否为True,并将所有测试(是否发生了应将标志设置为False的事件)都放在其他地方,从而让程序变得更为整洁。
下面来在前一节的程序中添加一个标志。我们把这个标志命名为active(可给它指定任何名称),它将用于判断程序是否应继续运行:
1 | |
而在这个程序中,我们使用了一个标志来指出程序是否处于活动状态,这样如果要添加测试(如elif语句)以检查是否发生了其他导致active变为False的事件,将很容易。在复杂的程序中,如很多事件都会导致程序停止运行的游戏中,标志很有用:在其中的任何一个事件导致活动标志变成False时,主游戏循环将退出,此时可显示一条游戏结束消息,并让用户选择是否要重新玩。
使用break退出循环
要立即退出while循环,不再运行循环中余下的代码,也不管条件测试的结果如何,可使用break语句。 break语句用于控制程序流程,可使用它来控制哪些代码行将执行,哪些代码行不执行,从而让程序按你的要求执行你要执行的代码。
在任何Python循环中都可使用break语句。例如,可使用break语句来退出遍历列表或字典的for循环。
在循环中使用continue
要返回到循环开头,并根据条件测试结果决定是否继续执行循环,可使用continue语句,它不像break语句那样不再执行余下的代码并退出整个循环。
例如,来看一个从1数到10,但只打印其中偶数的循环:
1 | |
避免无限循环
每个while循环都必须有停止运行的途径,这样才不会没完没了地执行下去。每个程序员都会偶尔因不小心而编写出无限循环,在循环的退出条件比较微妙时尤其如此。
如果程序陷入无限循环,可按Ctrl + C,也可关闭显示程序输出的终端窗口。要避免编写无限循环,务必对每个while循环进行测试,确保它按预期那样结束。如果你希望程序在用户输入特定值时结束,可运行程序并输入这样的值;如果在这种情况下程序没有结束,请检查程序处理这个值的方式,确认程序至少有一个这样的地方能让循环条件为False或让break语句得以执行。
使用while循环来处理列表和字典
到目前为止,我们每次都只处理了一项用户信息:获取用户的输入,再将输入打印出来或作出应答;循环再次运行时,我们获悉另一个输入值并作出响应。然而,要记录大量的用户和信息,需要在while循环中使用列表和字典。
for循环是一种遍历列表的有效方式,但在for循环中不应修改列表,否则将导致Python难以跟踪其中的元素。要在遍历列表的同时对其进行修改,可使用while循环。通过将while循环同列表和字典结合起来使用,可收集、存储并组织大量输入,供以后查看和显示。
在列表之间移动元素
假设有一个列表,其中包含新注册但还未验证的网站用户;验证这些用户后,如何将他们移到另一个已验证用户列表中呢?一种办法是使用一个while循环,在验证用户的同时将其从未验证用户列表中提取出来,再将其加入到另一个已验证用户列表中。代码可能类似于下面这样:
1 | |
输出结果:
1 | |
删除包含特定值的所有列表元素
我们使用函数remove()来删除列表中的特定值,这之所以可行,是因为要删除的值在列表中只出现了一次。如果要删除列表中所有包含特定值的元素,可不断运行一个while循环,直到列表中不再包含特定值。
1 | |
输出结果:
1 | |
使用用户输入来填充字典
可使用while循环提示用户输入任意数量的信息。下面来创建一个调查程序,其中的循环每次执行时都提示输入被调查者的名字和回答。我们将收集的数据存储在一个字典中,以便将回答同被调查者关联起来:
1 | |
如果你运行这个程序,并输入一些名字和回答,输出将类似于下面这样:
1 | |
函数
函数是带名字的代码块,用于完成具体的工作。要执行函数定义的特定任务,可调用该函数。需要在程序中多次执行同一项任务时,无需反复编写完成该任务的代码,而只需调用执行该任务的函数,让Python运行其中的代码。
定义函数
下面是一个打印问候语的简单函数,名为greet_user():
1 | |
这个示例演示了最简单的函数结构。 Ø处的代码行使用关键字def来告诉Python你要定义一个函数。这是函数定义,向Python指出了函数名,还可能在括号内指出函数为完成其任务需要什么样的信息。在这里,函数名为greet_user(),它不需要任何信息就能完成其工作,因此括号是空的(即便如此,括号也必不可少)。最后,定义以冒号结尾。
紧跟在def greet_user():后面的所有缩进行构成了函数体。 此处的文本是被称为文档字符串( docstring)的注释,描述了函数是做什么的。文档字符串用三引号 """ """括起, Python使用它们来生成有关程序中函数的文档。
函数调用让Python执行函数的代码。要调用函数,可依次指定函数名以及用括号括起的必要信息
向函数传递信息
可在函数定义def greet_user()的括号内添加username。通过在这里添加username,
就可让函数接受你给username指定的任何值。现在,这个函数要求你调用它时给username指定一个值。调用greet_user()时,可将一个名字传递给它,如下所示:
1 | |
你可以根据需要调用函数greet_user()任意次,调用时无论传入什么样的名字,都会生成相应的输出。
形参与实参
在函数greet_user()的定义中,变量username是一个形参——函数完成其工作所需的一项信息。在代码greet_user(‘jesse’)中,值’elysia’是一个实参。实参是调用函数时传递给函数的信息。
传递实参
鉴于函数定义中可能包含多个形参,因此函数调用中也可能包含多个实参。向函数传递实参的方式很多,可使用位置实参,这要求实参的顺序与形参的顺序相同;也可使用关键字实参,其中每个实参都由变量名和值组成;还可使用列表和字典。
位置实参
调用函数时, Python必须将函数调用中的每个实参都关联到函数定义中的一个形参。 为此,最简单的关联方式是基于实参的顺序。这种关联方式被称为位置实参。
为明白其中的工作原理,来看一个显示宠物信息的函数。这个函数指出一个宠物属于哪种动物以及它叫什么名字,示例如下:
1 | |
输出结果:
1 | |
调用函数多次
调用函数多次是一种效率极高的工作方式。在函数中,可根据需要使用任意数量的位置实参, Python将按顺序将函数调用中的实参关联到函数定义中相应的形参。
位置实参的顺序很重要
请确认函数调用中实参的顺序与函数定义中形参的顺序一致。
关键字实参
关键字实参是传递给函数的名称—值对。你直接在实参中将名称和值关联起来了,因此向函数传递实参时不会混淆。关键字实参让你无需考虑函数调用中的实参顺序,还清楚地指出了函数调用中各个值的用途。
下面来重新编写pets.py,在其中使用关键字实参来调用describe_pet():
1 | |
函数describe_pet()还是原来那样,但调用这个函数时,我们向Python明确地指出了各个实参对应的形参。看到这个函数调用时, Python知道应该将实参’hamster’和’harry’分别存储在形参animal_type和pet_name中。输出正确无误,它指出我们有一只名为Harry的仓鼠。
关键字实参的顺序无关紧要,因为Python知道各个值该存储到哪个形参中。使用关键字实参时,务必准确地指定函数定义中的形参名。
默认值
编写函数时,可给每个形参指定默认值。在调用函数中给形参提供了实参时, Python将使用指定的实参值;否则,将使用形参的默认值。因此,给形参指定默认值后,可在函数调用中省略相应的实参。使用默认值可简化函数调用,还可清楚地指出函数的典型用法。
例如,如果你发现调用describe_pet()时,描述的大都是小狗,就可将形参animal_type的默认值设置为’dog’。这样,调用describe_pet()来描述小狗时,就可不提供这种信息:
1 | |
请注意,在这个函数的定义中,修改了形参的排列顺序。由于给 animal_type指定了默认值,无需通过实参来指定动物类型,因此在函数调用中只包含一个实参——宠物的名字。然而, Python依然将这个实参视为位置实参,因此如果函数调用中只包含宠物的名字,这个实参将关联到函数定义中的第一个形参。这就是需要将 pet_name放在形参列表开头的原因所在。
使用默认值时,在形参列表中必须先列出没有默认值的形参,再列出有默认值的实参。
这让Python依然能够正确地解读位置实参。
等效的函数调用
鉴于可混合使用位置实参、关键字实参和默认值,通常有多种等效的函数调用方式。
请看下面的 函数describe_pets()的定义,其中给一个形参提供了默认值:
1 | |
基于这种定义,在任何情况下都必须给pet_name提供实参;指定该实参时可以使用位置方式,也可以使用关键字方式。如果要描述的动物不是小狗,还必须在函数调用中给animal_type提供实参;同样,指定该实参时可以使用位置方式,也可以使用关键字方式。
下面对这个函数的所有调用都可行:
1 | |
使用哪种调用方式无关紧要,只要函数调用能生成你希望的输出就行。使用对你来说最
容易理解的调用方式即可。
避免实参错误
等你开始使用函数后,如果遇到实参不匹配错误,不要大惊小怪。你提供的实参多于或少于函数完成其工作所需的信息时,将出现实参不匹配错误。
如果调用函数describe_pet()时没有指定任何实参,结果将如下————
1 | |
traceback指出了问题出在什么地方,让我们能够回过头去找出函数调用中的错误。如果这个函数存储在一个独立的文件中,我们也许无需打开这个文件并查看函数的代码,就能重新正确地编写函数调用。
Python读取函数的代码,并指出我们需要为哪些形参提供实参,这提供了极大的帮助。这也是应该给变量和函数指定描述性名称的另一个原因;如果你这样做了,那么无论对于你,还是可能使用你编写的代码的其他任何人来说, Python提供的错误消息都将更有帮助。
如果提供的实参太多,将出现类似的traceback,帮助你确保函数调用和函数定义匹配。
返回值
函数并非总是直接显示输出,相反,它可以处理一些数据,并返回一个或一组值。函数返回的值被称为返回值。在函数中,可使用return语句将值返回到调用函数的代码行。返回值让你能够将程序的大部分繁重工作移到函数中去完成,从而简化主程序
返回简单值
示例:
1 | |
调用返回值的函数时,需要提供一个变量,用于存储返回的值。
我们原本只需编写下面的代码就可输出整洁的姓名,相比于此,前面做的工作好像太多了:
1 | |
但在需要分别存储大量名和姓的大型程序中,像get_formatted_name()这样的函数非常有用。
让实参变成可选的
有时候,需要让实参变成可选的,这样使用函数的人就只需在必要时才提供额外的信息。可使用默认值来让实参变成可选的。
例如,假设我们要扩展函数get_formatted_name(),使其还处理中间名。为此,可将其修改成类似于下面这样:
1 | |
只要同时提供名、中间名和姓,这个函数就能正确地运行。然而,并非所有的人都有中间名,但如果你调用这个函数时只提供了名和姓,它将不能正确地运行。为让中间名变成可选的,可给实参middle_name指定一个默认值——空字符串,并在用户没有提供中间名时不使用这个实参。 为让get_formatted_name()在没有提供中间名时依然可行,
可给实参middle_name指定一个默认值——空字符串,并将其移到形参列表的末尾:
1 | |
Python将非空字符串解读为True,因此如果函数,调用中提供了中间名,if middle_name将为True。
返回字典
函数可返回任何类型的值,包括列表和字典等较复杂的数据结构。例如,下面的函数接受姓名的组成部分,并返回一个表示人的字典。
1 | |
这个函数接受简单的文本信息,将其放在一个更合适的数据结构中,让你不仅能打印这些信息,还能以其他方式处理它们。当前,字符串’jimi’和’hendrix’被标记为名和姓。你可以轻松地扩展这个函数,使其接受可选值,如中间名、年龄、职业或你要存储的其他任何信息。
结合使用函数和while循环
第二部分 实战演练
批量发送邮件 (方案已废弃 新实现见Python smtp发送邮件)
步骤:
- 批量读取文件内容;
- 通过账号密码登录邮箱;
- 设置邮件收件人等信息;
- 配置邮件正文和附件并发送。
批量读取文件内容
在 Windows 系统的路径中,我们使用反斜线 \ 分隔各个文件夹和文件名。同时,在路径的最前面,是盘符的字母和一个英文冒号,表示文件或文件夹具体是在哪个盘的路径下。变量 sender 存储发件人邮箱,字典 receiverDict 的键是收件人名字,对应的值为收件人的邮箱。
1 | |
使用 Windows 系统需要注意路径前要加一个 r,表示字符串不需要转义。
可以使用字符串拼接的方式,获得图片的路径。收件人姓名该如何获取呢?在这里,可以通过 for 循环遍历字典 receiverDict,得到字典的键。自然,这需要整理联系人与文件名时批量处理。
批量获得图片路径
接着,通过字符串拼接的方式,就可以批量获得图片路径。
1 | |
可以使用 with…as 语句配合 open() 函数的方式,打开图片
open() 函数用于打开一个文件,并返回文件对象。通常,open() 函数常用形式是接收两个参数:文件路径和打开方式。rb 表示以只读的方式读取二进制文件,即 Read Binary 的缩写。open() 函数还可以对文件进行写入。
open() 函数在读取文件时,有时候会发生异常。为了能在发生异常时,自动释放打开的文件资源,我们可以搭配使用 with...as...语句。使用 with...as...语句,首先执行 with 后面的 open() 函数,返回值会赋给 as 后面的变量。
当我们要打开一张图片就需要这几个部分: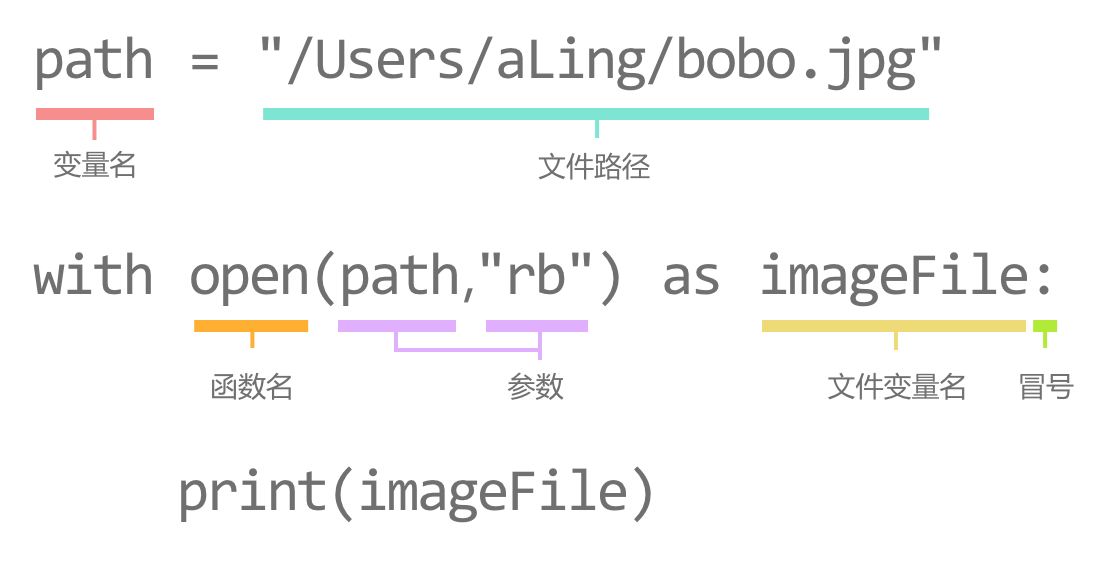
常见文件后缀名Filename Extension
批量读取图片。
在这里,我们可以调用 read() 函数,read() 函数可以逐个字节(或者逐个字符)读取文件中的内容。由于是以二进制格式打开图片,所以读取的图片内容是二进制格式。
这样,所有图片就以二进制格式保存下来。
通过账号密码登录邮箱
为了登录邮箱,我们先导入 smtplib 模块,smtplib 模块负责登录和发送邮箱的操作。
1 | |
邮箱服务器的功能:当发件人发出邮件时,会根据邮件地址发送给邮件服务器。之后,收件人登录自己的邮箱时,会从邮件服务器获取邮件,就能够查看到刚才发件人发出的邮件了。每个服务器有多个端口,只有通过端口号,程序才能访问到该服务器。
其他邮箱一般使用帐号和密码。而在代码中,需要用到帐号和授权码。授权码就是用于登录第三方客户端专用的密码,以QQ邮箱为案例,学习如何获取QQ邮箱中的授权码。
QQ邮箱设置
- 在浏览器中打开网址mail.qq.com,输入自己的帐号和密码,登录邮箱并找到「设置」
2.点击「设置」,找到「账户」。 - 滑动页面找到「SMTP服务」,选择第二项,点击「开启」。
4.「短信验证」点击「开启」后会弹出验证密保,需要用自己的手机号发送指定内容,发送完成后,点击「我已发送」。 - 完成验证后,将会获得一个「授权码」(授权码不要告诉其他人),复制并保存授权码, 这样我们就拿到了授权码。
在代码中需要先连接邮箱服务器,再登录邮箱。
- smtplib.SMTP_SSL(服务器地址, 端口号) —— 负责连接邮箱服务器。
- login(帐号, 授权码) —— 负责登录邮箱。
1 | |

设置邮件收件人等信息
编辑收件人等信息需要用到 email 模块,该模块中封装了很多方法。负责编辑收件人、发件人、主题等信息。
需要从 email.header中导入 Header 类,用于编辑发件人;从 email.mime.multipart中导入 MIMEMultipart类,用于整合邮件信息。
1 | |
- Header 负责编辑邮件内容。
message["From"] = Header("阿玲<aLing@qq.com>")表示先实例化一个 Header 对象,传入发件人信息;然后将发件人信息,赋值给 message[“From”]。
其他内容的编辑方式类似,实例化一个 Header 对象,将收件人信息写入 message 中的[“To”]字段中。将主题信息写入 message 中的[“Subject”]字段中。 - MIMEMultipart 负责整合邮件内容。
message = MIMEMultipart()—— 表示实例化一个 MIMEMultipart 对象,赋值给 message ,便于后面将邮件信息写入变量中。
1 | |
发送邮件
发送邮件使用 sendmail(),传入三个参数:
- 发件人邮箱 sender;
- 收件人邮箱 receiverDict[receiver];
- 邮件内容 message.as_string(),使用 as_string() 方法将message设置为文本格式。

配置邮件正文和附件并发送
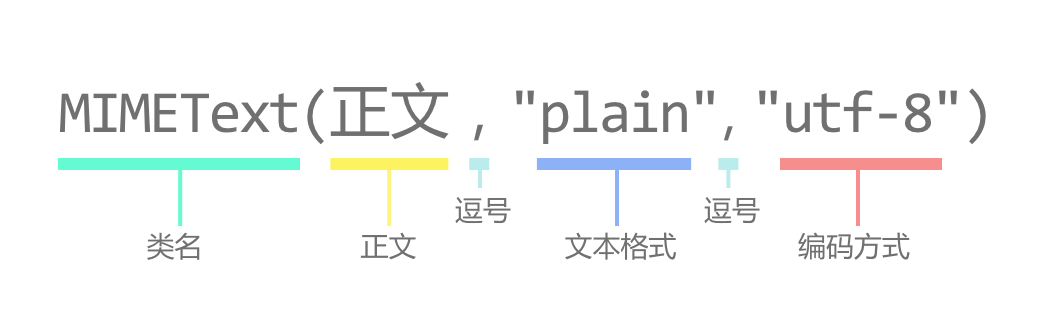
邮件正文需要使用 email.mime.text 下的 MIMEText 类。邮件正文需要创建 MIMEText 实例,传入三个参数:
- 正文:”Dear xx,邀请你参加年会。”;(可根据实际情况编辑内容。)
- 文本类型:”plain”;
- 编码:”utf-8”。
图片附件的处理
文件内容读取后,我们需要将图片文件编辑为邮件中需要的格式。从 email.mime.image 中导入 MIMEImage 类,用于图片附件的处理。
先创建 MIMEImage 实例,传递图片内容参数,再调用 add_header() 设置名称。
- 参数:”Content-Disposition”
- 参数:”attachment”
- 参数:filename=”邀请函.jpg”(文件名可根据实际情况编辑)。

正文和图片需要使用 message 调用 attach() 方法,传入相应的参数。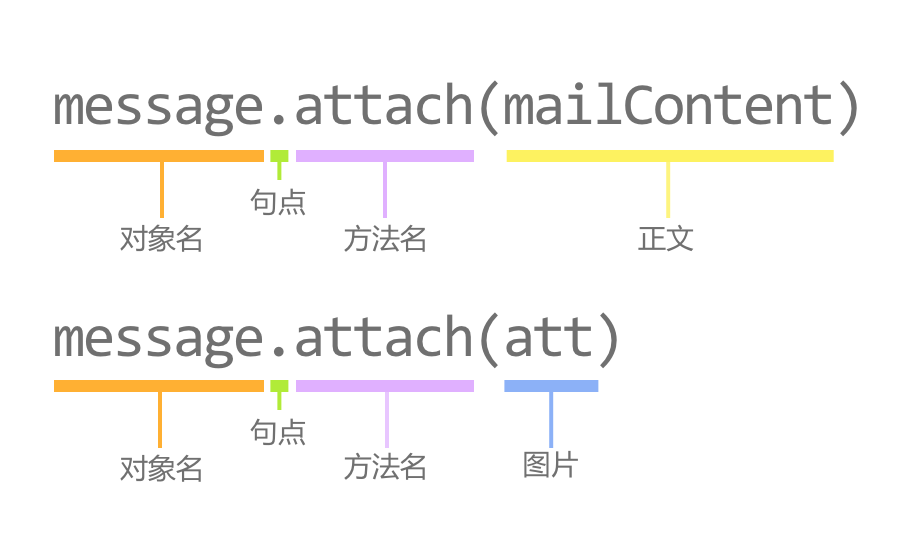
全部代码实现示例:
1 | |
Python smtp发送邮件
详见 https://docs.python.org/zh-cn/3/library/email.examples.html
SMTP
SMTP(Simple Mail Transfer Protocol)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。python的smtplib提供了一种很方便的途径发送电子邮件。它对smtp协议进行了简单的封装。
Python创建 SMTP 对象语法如下:
1 | |
参数说明:
- host: SMTP 服务器主机。 你可以指定主机的ip地址或者域名如:runoob.com,这个是可选参数。
- port: 如果你提供了 host 参数, 你需要指定 SMTP 服务使用的端口号,一般情况下SMTP端口号为25。
- local_hostname: 如果SMTP在你的本机上,你只需要指定服务器地址为 localhost 即可。
Python SMTP对象使用sendmail方法发送邮件,语法如下:
1 | |
参数说明:
- from_addr: 邮件发送者地址。
- to_addrs: 字符串列表,邮件发送地址。
- msg: 发送消息
这里要注意一下第三个参数,msg是字符串,表示邮件。我们知道邮件一般由标题,发信人,收件人,邮件内容,附件等构成,发送邮件的时候,要注意msg的格式。这个格式就是smtp协议中定义的格式。
使用QQ邮箱SMTP的简单实现:
1 | |
发送HTML格式的邮件
Python发送HTML格式的邮件与发送纯文本消息的邮件不同之处就是将MIMEText中_subtype设置为html。具体代码如下:
1 | |
发送带附件的邮件
发送带附件的邮件,首先要创建MIMEMultipart()实例,然后构造附件,如果有多个附件,可依次构造,最后利用smtplib.smtp发送。
1 | |
更多内容详见 https://www.runoob.com/python3/python3-smtp.html
Simpel AI samples
Introduction to Artificial Intelligence
人工智能之父
“让机器像人类一样思考”最早是由英国数学家艾伦·图灵于1950年发表的《计算机与智能》中提出。因此,图灵被称为计算机科学与人工智能之父。(图灵被印刷在50面额的英镑中)判断一个机器是否具有智能,可以使用图灵测试。
图灵测试——模仿游戏
图灵提出,要测试一个机器是否具有智能,只需要看它是否能成为一个“人类模仿大师”。测试具有聊天功能的机器人是否“智能”,我们可以让它模仿人类的说话习惯,然后与不同的测试人员聊天。
判断结果:若在规定的时间内,大部分测试人员没有意识到与他聊天的是机器人,那我们就认为该机器人是“人类聊天模仿大师”,即它是具有智能的。
图灵的想法引起多位学者的重视,开启了探讨人工智能的热潮。基于设定好的条件规则,能够进行自动判断的程序问世,从而搭建了问题处理系统。专家系统就是其中之一,它被认为是最早期的“人工智能”。
专家系统 Expert system
定义:将某个领域专家水平的知识作为数据存储起来形成“知识库”,并把其经验设定为规则条件,就构成了一个能够自动解决该领域问题的程序。该程序称为专家系统。
简单来说,早期的“人工智能”程序由大量的字典等内容组成数据储备,并用固定数量的条件规则作为逻辑。机器在遇到问题时,通过规则从数据中查找答案。因为所有的规则都由人工录入,所以机器并没有真的“思考”。
为此,美国哲学家约翰·希尔勒提出了“中文房间”的实验。
中文房间
对于一个英语母语者来说,若为他提供足够的翻译书籍工具与查阅这些资料的时间,他就能够正常的通过文字与中文使用者交流。但实际上我们认为他并没有学会中文,因为他无法处理数据以外的内容。
图灵的遗憾
人们认识到,要想实现真正的人工智能,除了读取固有的数据以外,还需要让电脑对未知的数据进行预测。但限于当时计算机硬件的发展,直到图灵去世都未有一台机器通过图灵测试。
时间回到现在,随着计算机硬件大幅度升级,电脑的存储区域呈爆炸性增长。人们提出了以统计学等数学方法为基础的新“人工智能” —— 机器学习。
机器学习 Machine Learning
定义:机器学习是一门多领域交叉学科。主要通过概率论、统计学等数学方法,让机器从已知数据中模拟或实现人类的学习行为,找出规律并自动生成规则,然后对未知的数据进行预测。这就是机器学习的过程。
机器学习是实现人工智能的一种方法,是使计算机具有智能的根本途径。相较于直接使用数据储备,机器学习的目的是从已有的数据中挖掘规则,从而实现对未知的数据进行“预测”。
机器学习中存在的算法:线性回归、K近邻、朴素贝叶斯、决策树、逻辑回归、聚类算法、支持向量机、EM算法。
自然语言处理
要实现从评价中提取高频关键词,并判别其正负面性,其实是通过人工智能领域中的一个分支:自然语言处理。
自然语言处理 Natural Language Processing(NLP)
自然语言,即人们日常使用的语言,也就是每天包围着我们的文本信息和语音信息。自然语言处理(Natural Language Processing,简称NLP)研究的是如何通过机器学习等技术,让计算机学会处理自然(人类)语言,以完成有意义的任务。它是一门交叉学科,涉及计算机科学、语言学、数学等多个领域的专业知识。
相关案例
邮件过滤:
系统会根据电子邮件的内容识别电子邮件是否属于三个类别(重要、社交或广告)之一,或者判断一封邮件是否是垃圾邮件。
此时就是通过NLP来对这些邮件进行一系列的分类。搜索引擎,如百度、谷歌等。
在我们输入2-3个字后,搜索引擎会显示可能的搜索词。或者如果输入了错别字,搜索引擎会自动进行更正。这就是通过NLP技术来实现的搜索自动完成和自动更正功能,帮助我们更有效地找到准确的结果。机器翻译,比如Google、有道翻译。
目前所追求的翻译,不再仅仅是通过计算机直接将一种语言转换为另一种语言,而是需要像人类一样能够理解世界知识和上下文。要让电脑像人类一样理解自然语言,必然离不开NLP技术。语音助理,比如Siri、智能音箱等。
现在的语音助理,与人类之间的交流不再是简单的你问我答,不少语音助手甚至能和人类进行深度交谈。同样在这背后离不开NLP技术,使得语音助理能够将人类语言转换为机器语言,然后执行相应的操作。
自然语言处理的意义和难点
在面对自然语言时,除了单纯地阅读和倾听外,往往会进行更多复杂的操作和处理。但人工处理的代价过于高昂,因此会期望训练计算机来代替人类,这就是自然语言处理的意义。
然而,自然语言并没有想象中那么容易处理。与人工语言(编程语言或数学语言等)相比,自然语言有着多变、非结构化等各种特殊和复杂的特点。
例如:编程语言中的关键词数量是固定的,而自然语言中能使用的词汇量是无限的,甚至还在不断创造新词;编程语言具有结构性,如类和对象,但显然自然语言不具有这样的结构。
在自然语言中,不同的语境、句法和语义也会传达出不同的信息。比如,“我瞒着妈妈和姐姐出去玩了”这句话,如果没有指明「和」这个字的词性,就可以被理解为两种意思。
我瞒着妈妈和姐姐出去玩了我瞒着妈妈和姐姐出去玩了
广义上来讲任何处理自然语言的计算机操作都可以被理解为NLP。它可以实现一些简单的功能,比如短语之间的翻译。同时,NLP也致力于完成一些具有挑战性的任务,比如完全 “理解” 人类话语。
分词
一篇文本是由无数句话组成,而一句话又是由一个个词语组成,因此可以将词语看作是自然语言的基本单位。那么在进行NLP时,就需要先将句子中的词语分开。
对于英文,只需要按照空格和标点符号就可以将词语分开。但在中文文本里,所有的字都连在一起,计算机并不知道一个字应该与其前后的字连成词语,还是应该自己形成一个词语。因此,需要借助额外的工具将中文文本中的词语分隔开。这项技术被称为中文的分词。
分词完成后,就可以根据这些词语找到属于这个文本的特点,也就是常说的特征(feature)。对于文本而言,词语出现的频率就可以作为一项特征。那么,词频这个特征就能帮我们提取出关键词。在进行NLP时,构造词袋模型(Bag-of-Words Model)是一种常用的用于统计词频的技术。
词袋模型 Bag-of-Words Model
定义:词袋模型是一个描述文本的模型,用于统计每个词在文本中出现的次数。该模型只记录每个词语出现的次数,而忽略语法细节和词语之间的顺序。
例如,对于这条评价:满意物流,也满意屏幕大小在构建词袋模型前,需要先进行分词。这条评价按照一定方法分隔后,就变成了:满意 / 物流 / 也 / 满意 / 屏幕 / 大小
分隔后,词袋模型会统计每个词在文本中出现的次数:满意:2,物流:1,也:1,屏幕:1,大小:1
可以看到,通过词袋模型生成的结果,词的顺序和语法都被忽略了,变成了一些词语间的组合,但又在一定程度上保留了主题信息。将复杂的词句结构降维成体现主题的词语计数,以便计算机进行后续的处理,这就是词袋模型的基本思想。